Step 7 - Publishing, Persistent Identifiers and Preparing for Reuse
Last updated on 2025-01-28 | Edit this page
Estimated time: 21 minutes
You are nearing the end of this project, and need to start preparing for publication. What needs to be done?
Opportunity to ask people for ideas on what needs to be done, either on whiteboard or in chat.
Resources
Does your institute have a ‘Once your project is done’ checklist?
May be worth checking with your library or research office.
Persistent Identifiers
Identifiers vs Persistent Identifiers
What is the difference?
An identifier is any label used to name an item (whether digital or physical). URLs and serial numbers are an examples of digital identifiers. Personal names are also identifiers, but are not necessarily unique as you may share the same name with other researchers around the world.
Examples of identifiers:
URL: https://www.griffith.edu.au/eresearch-services/hacky-hour would direct to the correct website…. until the team got renamed during a restructure.
Barcode: 32888493 may work in a lab, however may not be unique outside a lab. Or the product making the barcode may be discontinued.
A persistent identifier is long-lasting unique digital reference to a webpage, digital object, even a person.
DOI
ORCID
This video from Research Data Netherlands explains persistent identifiers and data citation.
Let’s go into these in more detail.
Digital Object Identifiers (DOIs) - Identify information
Digital Object Identifiers (DOIs) are used to uniquely identify digital research objects, and provide a persistent link to the location of the object on the internet. They also enable citation and tracking of citation metrics.
A DOI is a unique alphanumeric string that identifies content and provides a persistent link to its location on the internet. Metadata for that object is collected, including attributions, and attached to a DOI.
They are the global standard for digital scholarly publications.
A DOI looks like this: https://doi.org/10.31219/osf.io/8v2n7
Minting DOI
Include information around who mints DOIs at your organisation.
Often, your institute library will mint a DOI for you.
Journal publishers assign DOIs to electronic versions of individual articles & datasets.
In addition, Open Science Framework can mint a DOI for your repository.
ORCID - Identify a person
ORCID Open Researcher and Contributor ID provides a persistent digital identifier (an ORCID iD) that you own and control, and that distinguishes you from every other researcher.
You can connect your ID with your professional information — affiliations, grants, publications, peer review, and more. You can use your ID to share your information with other systems, ensuring you get recognition for all your contributions, saving you time and hassle, and reducing the risk of errors.
An ORCID looks like https://orcid.org/0000-0002-0838-1771 .
This can assist people to find you :
When you move across institutes
If you have a common last name
If you change your name
Deposit your final data/analysis
Let’s get your work deposited so that others may access it.
Discussion
Unsure about publishing your data and pipelines publically?
Let’s look at our options.
Open vs FAIR vs Can’t share
Firstly, if you can share your work openly - Great!
Learn more about the distinction between open data, FAIR data and Research Data Management here.. Considering why you should share your data? Check this video
Does your institute have a policy, statement, procedure or resources on open access or publishing data and materials openly?
Link to them here.
You can also find examples of who has published openly in your institute.
Have you got an open network?
Prior to sharing, ensure you have clearly defined the licence, IP and attribution attached to your work.
Link to your organisation’s IP/Copyright person.
There are plenty of reasons you may not be able to share your data and pipelines openly.
In these cases, you could consider making your data as FAIR as possible.
This means you want to share the data, have it well described and have it in a good shape for sharing, but you can mediate requests and access.
Mediation of access can include caveats such as the need for a Data Transfer Agreement, limitations according to the ethics and governance, or other controls.
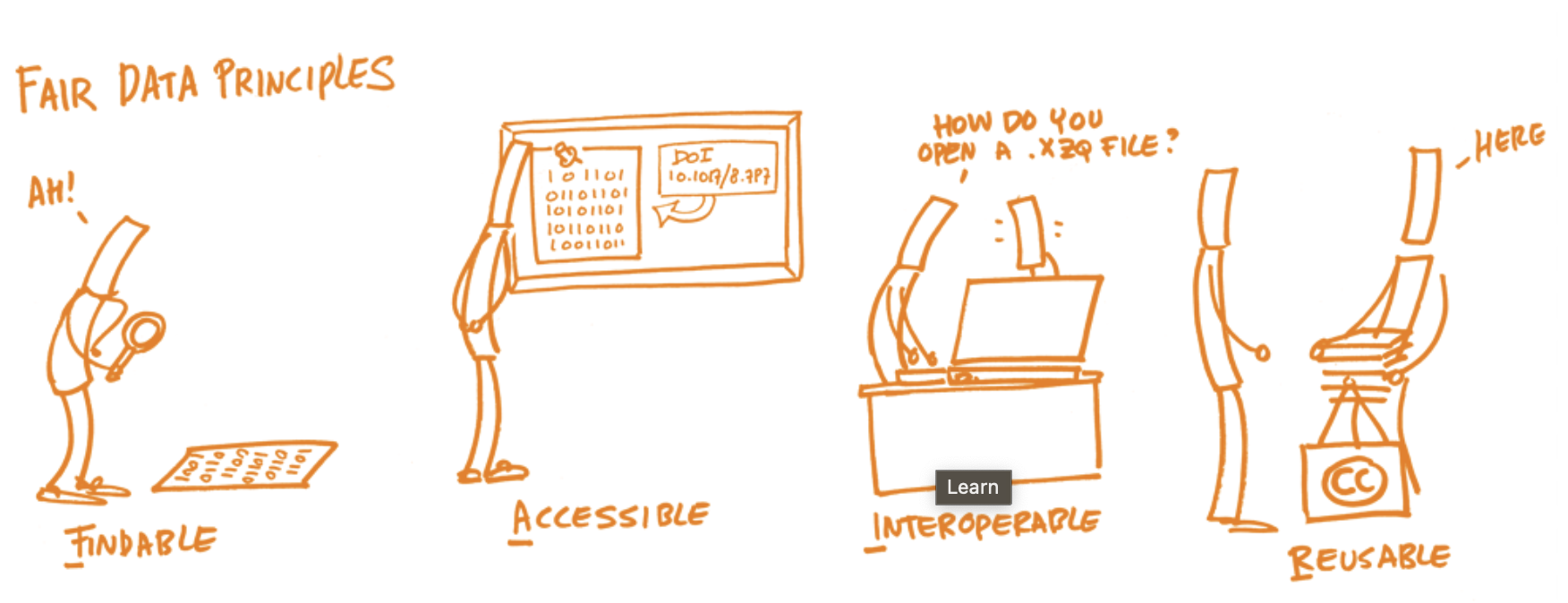
More information on FAIR can be found here
Licensing
When publishing supplimentary data, or wanting to share code, analysis pipelines, any datasets or other grey outputs, it is incredibly important to attach a license.
A licences provides guidence and sets legal obligations on
Who can reuse this material and for what?
Can this be used commercially?
No warranties are given or similar
If someone uses your work as part of their project, are they obligated to also use the same license?
Do they need to attribute your work?
Attribution especially is very important as it can help with redirecting people to your original work and builds your reputation.
This guide on licencing from OSF is a good place to start on what are the different types of licenses, what are the restrictions on each, how to license material such as preprints, registrations and projects and more.
Connect with your organisation’s IP, Copyright and Commercialisation team for more assistance.
Link to your organisation’s commercialisation team.
Resources
Here’s a great guide on Publishing with sensitive data
Where to deposit?
Deposit final state data to support your publications in an institutional or discipline data repository which can mint a DOI and create a citation for your work.
Here is a helpful guide to choosing a data repository
Some repositories include:
Can you also publish your raw data?
Publishing negative results
While it can be disheartening to get negative results, these results are still beneficial to the research community at large.
You worked out something didn’t work, which is important knowledge all in itself. Sharing this means others don’t need to reinvent the wheel, saving research effort and time.
There are a number of journals that specialise in these results.
Journal of Articles in Support of the Null Hypothesis
Information worth including in your paper or repository
Have limitations of the study been noted and justified/discussed?
Have you discussed how you handled missing data?
Should you include a reflective statement, with consideration on how your own bias/ priviledges/ world views may impact the findings?
What if a collaborative relationship sours?
Imagine you have been working with a collaborative partner in a different organisation. As you finish your project, they state that they are no longer interested in working together and are going to apply for the next grant with another partner.
How will this affect you?
What steps have we taken so far to help protect our position?
This may affect you
However, we’ve already taken steps to protect ourselves and safeguard against any potential fallout.
We’ve documented our ethics and governance documents and have clarified the conditions around reuse of the data, whether the data can be shared and what the data can be used for.
We’ve licensed our pipelines and data to specify whether it can be reused or if it can be commercialised, and if we need to be cited.
Useful Resources
Ten simple rules for improving research data discovery
Ten simple rules for getting and giving credit for data
Publishing a Jupyter notebook in a Findable, Accessible, Interoperable and Reusable (FAIR) way
Discontinuing a research software project?
CESSDA Training Team (2017 - 2022). CESSDA Data Management Expert Guide. Bergen, Norway: CESSDA ERIC. Retrieved from https://dmeg.cessda.eu/Data-Management-Expert-Guide/6.-Archive-Publish licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
DOI Decision Tree for Data Managers Retrieved on 2024-04-17 at https://ardc.edu.au/resource/doi-decision-tree/ licenced as CC BY 4.0 as per https://au.creativecommons.net/attributing-cc-materials/
What is your next step?
References
ARDC (2024) ‘FAIR data’. Retrieved from https://ardc.edu.au/resource/fair-data/ licenced as CC-BY-4.0
Project completion checklist by @cbahlai licenced under Public Domain
Contaxis N, Clark J, Dellureficio A, Gonzales S, Mannheimer S, Oxley PR, et al. (2022) Ten simple rules for improving research data discovery. PLoS Comput Biol 18(2): e1009768. https://doi.org/10.1371/journal.pcbi.1009768 licenced under CC-BY
ORCID (2024) Main Page. Retrieved on 2024-04-18 at https://orcid.org/ licenced as Public Domain.
Wood-Charlson EM, Crockett Z, Erdmann C, Arkin AP, Robinson CB (2022) Ten simple rules for getting and giving credit for data. PLoS Comput Biol 18(9): e1010476. https://doi.org/10.1371/journal.pcbi.1010476
Image:
As per Sonja Bezjak, April Clyburne-Sherin, Philipp Conzett, Pedro Fernandes, Edit Görögh, Kerstin Helbig, Bianca Kramer, Ignasi Labastida, Kyle Niemeyer, Fotis Psomopoulos, Tony Ross-Hellauer, René Schneider, Jon Tennant, Ellen Verbakel, Helene Brinken, & Lambert Heller. (2018). Open Science Training Handbook (1.0)]. Zenodo. https://doi.org/10.5281/zenodo.1212496 , Retrieved 2024-04-19 from https://open-science-training-handbook.gitbook.io/book/02opensciencebasics/02openresearchdataandmaterials#undefined-3 licenced as CC0 Universal Public Domain.
In this lesson, we have learnt:
What the difference is between an identifier and a persistent identifier
What a DOI and ORCID is
How to get a DOI minted for your articles and datasets
If and how to share your datasets
What FAIR sharing is, and how mediated sharing works
What to consider for licensing
Where you can deposit your datasets or grey materials
Negative results and how this still can be important to publish
We build trust in our knowledge by:
Publishing our data with a license, so that others can reuse it
Sharing your data as FAIR, so that people can find you and request your data in a safe way
Helping people track who you are via an ORCID id